
Why Data Debt Is the Next Technical Debt You Need to Worry About
Real-Life Consequences and Lessons Learned

🚀We are now more than 200 people in this group. Thank you again for sticking with me on this journey🚀
In the last article about How Shadow Data Teams Are Creating Massive Data Debt, I mentioned how data debt affects the outcomes of a data team in the long term. Make sure you read it as it is an important heads-up for this article.
👋If you are a new reader, my name is Diogo Santos. I write about data product principles, the evolution of the modern data stack, and the journey to data mesh (the future of data architecture).
In today’s article, I will talk about data debt. I will discuss the differences between technical debt and data debt, what leads to it, real-life examples, possible consequences, and what can be done to avoid and manage it.
Please consider subscribing if you haven’t already. Reach out on LinkedIn if you ever want to connect.
Tags: Data Engineering | Data Debt | Technical Debt | Data Governance
What is data debt?
Data is becoming the lifeblood of modern organizations, and the amount of data generated and collected is increasing exponentially. To manage this data effectively, many organizations are building data lakes and data warehouses to store and process their data. However, the sheer volume and complexity of data are leading to a new type of technical debt called data debt.
While technical debt is well understood in the software development industry, data debt is a relatively new concept, but quickly becoming a significant concern for all data teams, especially the ones in large organizations where multiple data initiatives have been put in place over the years.
Like technical debt, data debt is the cost of avoiding or delaying investment in maintaining, updating, or managing data assets, leading to decreased efficiency, increased costs, and potential risks.
Technical debt is a metaphor used in software development to describe the consequences of cutting corners to deliver a product quickly, without paying attention to code quality, maintainability, or scalability. It results from various factors such as time constraints, a lack of resources, or the need to meet a deadline.
It can be managed by refactoring code, rewriting the code, or gradually improving the code over time.
Similarly, data debt is the result of neglecting data assets' maintenance, leading to data inconsistencies, redundancies, and inaccuracies.
Data debt differs from technical debt in two ways:
Technical debt is often associated with code, whereas data debt is associated with data assets such as databases, data warehouses, and data lakes.
Technical debt is caused by the trade-off between short-term goals and long-term investment, while data debt is caused by the proliferation of data silos, duplication, and inconsistencies.
Why is data debt emerging?
Several factors are contributing to the rise of data debt in organizations:
The accumulation of vast amounts of data over the years and the exponential growth of data have led to the proliferation of data silos, making it challenging to maintain a centralized view of data assets. The huge volume from several different sources being ingested in the lake is increasing the chances of data debt if a proper process is not put in place.
The lack of data governance policies has resulted in data inconsistencies, redundancies, and inaccuracies. The possibility of creating new tables without control, lack of standard naming conventions, documentation not part of the data development cycle, and lack of ownership, are some concrete examples of that.
The lack of data literacy and data-driven culture has led to a lack of awareness of the importance of data assets and the cost of data debt. Educating the organization about the importance of handling data is hard since today’s business world requires agile deliveries.
Data is often managed by multiple teams, each with its own tools and processes. This can lead to inconsistent data definitions and concepts with different meanings to different departments, making it difficult to ensure data quality. For example, suppose one team defines a customer as anyone who has made a purchase in the last six months, while another team defines a customer as anyone who has made a purchase in the last year. In that case, it becomes difficult to get a clear understanding of the customer base.
Organizations that have undergone rapid growth or mergers and acquisitions. When new teams or business units are added, it can be difficult to integrate their data with the existing systems, leading to data silos and redundancies.
How does data debt look in your daily life?
Let’s see some real-life examples:
Dashboards/Tables that were built but the business is not using
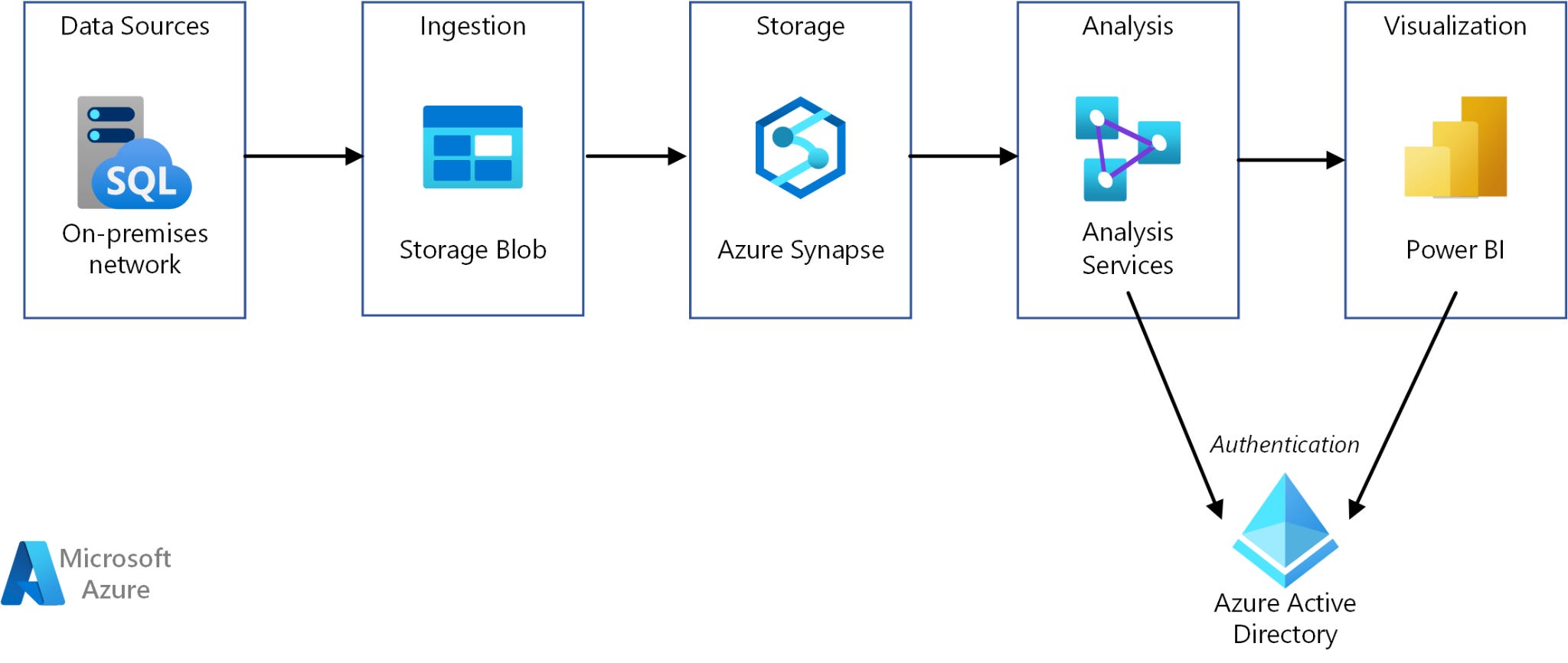
Datasets were once created but unused by the organization either in direct queries or in the organization’s BI tool.
Several resources were/are being spent on this process to clean and maintain this data. Several tables were created to feed the dashboard. Several new data objects were added to the data warehouse with no value, just generating additional confusion for data consumers.
The consequences? More confusion in the warehouse. More pipelines to manage. More tables to handle.
SQL Spaghetti Data Pipelines

Often, data scientists to ensure short insights-to-market, can’t wait for the perfect dataset from the data engineering team.
So, they build their own pipelines, through SQL or DBT without ensuring proper software engineering best practices (modularity, versioning, CI/CD, documentation) and without thinking about how other business teams might consume this data in the future.
The consequences? Several other objects are built on top of this dataset, generating a huge risk for the business.
No proper data contracts/collaboration between software and data engineers

The data and architecture from production systems were never intended for analytics. Thus, through ELT/CDC pipelines, data teams end up ingesting data that they don’t fully understand, generating “non-consensual” APIs.
A “non-consensual” API is when you consume data from an interface without restrictions and conditions that normal APIs would enforce. An S3 dump or a connection to a database for ETL is a “non-consensual” API.
The software engineering team, which is not involved in the analytical cycle, later on, modifies an element (like a column name or format) in a table from a production system. This small change can easily break an important pricing model which was key for the organization because it was consuming data from this production table.
The software engineering team didn’t alert the data team that such a change would happen. Why? Because they don’t know that they have to. This is what I called the lack of collaboration between teams.
This is one of the main reasons why much of the data engineering time is spent fixing bugs. Because production systems changed either on architecture, tables name, or columns business logic, forcing changes in the data infrastructure and data pipelines.
The consequences? The data engineering becomes a reactive team. They have no time to fulfill a new request. Analytics and ML Teams have to wait weeks to get a new dataset.
Data ingested in the lake that the data team doesn’t fully understand

With the rise of Cloud Data Lakes, storing data has never been cheaper.
Thus, data from several sources are being centralized with no control, creating space for data quality issues.
As I wrote in a previous article, in the first-generation data architectures called data warehousing, the data modeling was very rigid forcing data to have contextual and semantic meaning. Any user would be able to follow the data modeling and understand the objective of each table and how the business was operating.
With the arrival of the data lake architecture, data started to be ingested from operational systems, 3rd party APIs, and front-end events such as Snowplow. This proliferation of data sources killed data modeling.
The result is that most organizations have so much different data in the data lake that became very hard to have a comprehensive understanding of our data and its semantic meaning.
The consequences? No one in the organization can be sure about the quality of the data used in analytics or machine learning. When a change is needed it takes weeks, to months.
Data product ownership/accountability

This point is often generated by the lack of data governance and shadow data engineering as we saw in the previous article.
No clear ownership over objects in the data stack, generating questions such as 'Who owns this table?' 'Who is on the hook to fix it when it breaks?' 'Why does data engineering keep telling me they don't have a context?'
The consequences? When something breaks, if there’s no ownership of the object with a problem, nobody will solve it. Teams will most likely generate additional debt by handling this error on their code rather than ensuring the problem is fixed at the source.
No Documentation

Data is not being cataloged or categorized. Lack of documentation of upstream and downstream data products. A huge struggle to understand what each column means and which data and business logic were used to build it. Lack of information on why certain decisions on the machine learning pipeline development were made.
A terrible experience navigating in the warehouse because we have no idea what a huge number of tables are doing there. It’s hard to explore and get information without consulting data engineers or even the software engineering team.
Documentation when exists is very hard to find and understand or it was not updated with the schema changes.
The experienced data engineer/scientist leaves the organization and takes years of knowledge with him.
What are the consequences?
Let’s be clear about this. The biggest impact of data debt is decreased productivity and increased costs.
Data debt will increase the number of steps you need to execute to complete a task. It will require more resilience from data teams.
Whenever you need to create or change something in your data stack, you will spend a large part of your time, changing or correcting one or more precedent data object built years ago by someone who’s no longer at the organization.
The worst part? By changing a precedent data object required for your new task, you’re assuming the risk of potentially break a critical pipeline or other data asset for the business that was also depentent on that same data object.
These consequences of data debt can be significant. Inaccurate or incomplete data can lead to poor business decisions, missed opportunities, and lost revenue. It can also lead to regulatory compliance issues and reputational damage if data breaches occur. Additionally, the cost of maintaining and cleaning up data debt can be significant, both in terms of time and resources.
Longer time to market
It is more difficult to work with low-quality data sources than high-quality ones. This is due to increased effort to understand the data sources, evolve them, and then test them to ensure they still work as expected.
Increased Costs
The increased time to work with lower-quality data sources results in increased costs to do so. Much more time needs to be invested in any data initiative. At some point, more planning is also needed to work within an environment with data debt.
Unexpected Problems
Data debt is hidden, thus it becomes difficult to predict how much effort it will be to work with existing data sources because you often don’t know how big the mess is until you investigate the situation.
Even when you do, you always run into unexpected problems when you start the actual work.
Poor Decision Support
Poor quality data, either due to inconsistencies, lack of timeliness, inaccuracies, or many other issues will impact downstream decision-making in the organization.
Decreased Collaboration
The decreased collaboration is often the result of "finger-pointing". The developers didn't work with the source of record, the data people were too hard to work with, this team didn't keep the documentation up to date, and so on.
How should data teams manage data debt?
Before talking about how to manage data debt, it’s important to remind that we should always try to avoid it first. Organizations must prioritize data quality, incentive good practices, the collaboration between teams, the ownership over what is built, and they need to make boring work such as documentation part of the development cycle.
Now, to address the already created data debt, we need to think about how Chief Financial Officers manage financial debt. The CFO doesn’t simply pay all the debt, even if that would be possible, because he needs to consider the cost of paying it.
When tackling any type of debt, we should think about the cost of opportunity. Here’s an example:
Financial Debt - “Before using this money to reduce my debt which has an annual interest rate of 15%, is there any investment where the same money could have an annual return of 19% (let’s put risk aside on this example)?” If yes, then the choice is obvious. The CFO would prefer to generate the revenue first.
Data Debt - “Before investing 3 weeks refactoring this pipeline, is there any use case where my time will generate a bigger return than the cost of no refactoring?” If yes, then you should spend your time where the value is higher.
What I’m saying here is that just paying out the debt with no strategy is a waste of time and resources. Here’s what you should rather do according to Chad Sanderson:
Don't focus on everything. Identify the most impactful use cases.
Define an ROI-generating use case and work backward. That’s how you related data debt to business impact.
Define how improving quality will improve business outcomes
Start with ownership and lineage. Understand the data flow.
Help upstream teams understand the impact of breaking changes.
Help downstream teams identify who to talk to for escalations.
Find the smallest atomic unit of ownership that adds value.
Drive ownership, tooling, and reporting for that atomic unit.
Repeat and expand.
What comes next?
If you have been reading this publication you have noticed that I have been highlighting the problems that we face in the data industry, mostly because we have been dealing with data from a purely technical perspective.
My objective is to generate awareness around these problems and get people to relate to my examples because they are real-life stories.
Thus, in the upcoming weeks, I will be sharing additional content about
Why a data warehouse is the most important data asset in the organization
After those, I will start finally introducing data mesh.
If this is relevant to you, make sure you subscribe. Feel free to suggest in the comment section any other topic that you would like to see covered. That will help me to focus my writing on your problems.
Make sure you follow me on LinkedIn for more weekly posts, and if you liked my article, please consider subscribing.
Thank you so much for reading and let’s talk again soon.