
The Past, Present, and Future of Data Architecture
A journey trough time and the introduction to data mesh

🚀We are now hitting the +100 subscribers milestone, 3 months after the 1st post.🚀
When I started writing, I never thought I would find so many people interested in what I have to share. So, thank you so much for making this journey alongside me.
👋If you are a new reader, my name is Diogo Santos. I write about data product principles, the evolution of the modern data stack, and the journey to data mesh (the future of data architecture).
In today’s article, I will talk about the evolution of data architectures. What motivated the architectural changes and their impact on data initiatives. I will be introducing data mesh, the latest generation of data architectures. Please consider subscribing if you haven’t already.
Reach out on LinkedIn if you ever want to connect.
Tags: Data Architecture | Data Mesh | Data Lake | Decentralized Data Ownership
Why do we need data architecture?
Becoming a data-driven organization remains one of the top strategic goals of many companies. Data-driven means placing data at the center of all the decisions and processes that are made in the organization.
Leaders understand that becoming data-driven is the only way to improve customers’ experience, through hyper-personalization and customer journey re-design, to reduce operational costs through automation and machine learning, and to understand business trends which are important for high-level strategy and market positioning. A data platform creates a prosperous environment for data to thrive.
A data platform is a repository and processing house for all of the organization’s data. It handles the collection, cleansing, transformation, and application of data to generate business insights. It is sometimes referenced as a “modern data stack” since the data platform is often comprised of multiple integrated tools supported by different vendors (Dbt, Snowflake, Kafka, among others).
One of the main elements of your data platform is the data architecture. Data architecture is the process of designing, building, and managing the structure of the organization’s data assets. It’s like a framework for integrating data from different sources and applications.
The main goal of a well-designed data architecture is to reduce data silos, minimize data duplication and improve the overall efficiency of the data management process.
As the data landscape evolved during the last decades so did data architecture. Let’s see that evolution in more detail.
Analytical data has gone through evolutionary changes, driven by new consumption models, ranging from traditional analytics in support of business decisions to intelligent products augmented with ML

First Generation: Data Warehouse Architecture
The data warehouse architecture is defined by the data movement from operational systems (SAP, Salesforce) and 1st party databases (MySQL, SQL Server) to business intelligence systems. The data warehouse is the central point in which a schema is defined (snowflake schema, star schema) and where data will be stored in dimensions and fact tables, allowing businesses to trace and follow changes in their operations and customer interactions. Data is:
Extracted from many operational databases and sources
Transformed into a universal schema—represented in a multidimensional and
time-variant tabular format
Loaded into the warehouse tables through a CDC (change data capture) process
Accessed through SQL-like queries
Mainly serving data analysts for reporting and analytical visualization use cases
In this architectural style, data marts also come into action. They are an additional layer (composed of one or multiple tables) on top of the data warehouse to serve specific department business problems with a specific schema format. Without data marts, these departments would have to explore and create multiple queries in the warehouse to have the data with the content and format they need.
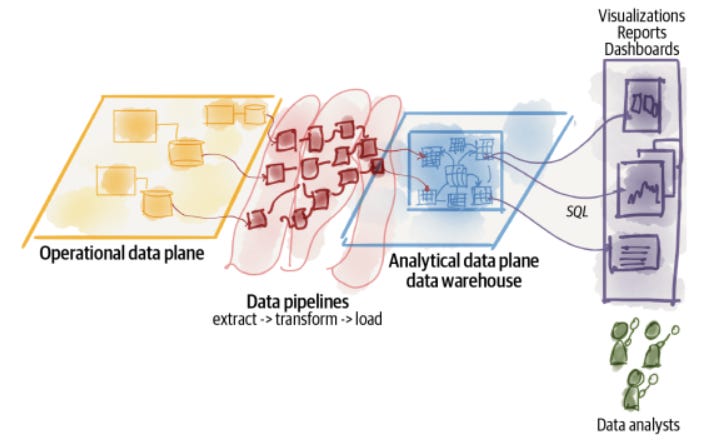
Main challenges of this approach:
Over time, thousands of ETL jobs, tables, and reports are built that only a specialized group can understand and maintain.
Modern engineering practices such as CI/CD are not applied.
The data model and schema design for data warehouses is too rigid to handle a huge volume of structured and unstructured data from multiple sources.
This leads us to the next data architecture generation.
Second Generation: Data Lake Architecture
Data lake architecture was introduced in 2010 in response to the challenges of data warehousing architecture in satisfying the new uses of data: access to data by data scientists in the machine learning model training process.
Data scientists need data in its original form for the machine learning (ML) model training process. ML Models also require massive loads of data, which can be hard to store in a data warehouse.
The first data lakes built involved storing data in the Hadoop Distributed File System (HDFS) across a set of clustered compute nodes. Data would be extracted and processed using MapReduce, Spark and other data processing frameworks.
Data lake architecture works under the ELT process, rather than the ETL process. Data gets extracted (E) from operational systems and loaded (L) into a central storage repository. However, unlike data warehousing, a data lake assumes very little or no transformation and modeling of the data upfront. The goal is to retain the data close to its original form. Once the data enters the lake, the architecture gets extended with data transformation pipelines (T) to model the raw data and store it in the data warehouse or feature stores.
Data engineering teams, to better organize the lake, create different “zones”. The goal is to store the data according to the degree of cleansing and transformation, from the rawest data to data enrichment steps, to the cleanest and most accessible data.
This data architecture aims to improve the ineffectiveness and friction of extensive up-front modeling that data warehousing requires. The up-front transformation is a blocker and leads to slower iterations for data access and model training.
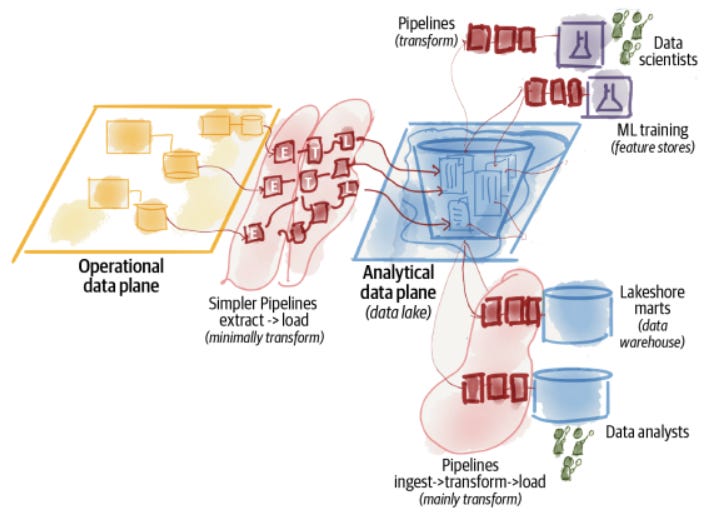
Main challenges of this approach:
Data lake architecture suffers from complexity and deterioration resulting in poor data quality and reliability.
Complex pipelines of batch or streaming jobs operated by a central team of
hyper-specialized data engineers.
It creates unmanaged datasets, which are often untrusted and inaccessible, providing little value
The data lineage and dependencies are hard to track
Having no extensive up-front data modeling creates difficulties to build a semantic mapping between different data sources, generating data swamps.
Third Generation: Cloud Data Lake Architecture
The biggest changes from second-generation to third-generation data architecture were the switch to the cloud, the real-time data availability, and the convergence between the data warehouse and the data lake. In more detail:
Support streaming for near real-time data availability with architectures such as
Kappa.
Attempt to unify batch and stream processing for data transformation with
frameworks such as Apache Beam.
Fully embrace cloud-based managed services and use modern cloud-native
implementations with isolated computing and storage. Storing data becomes much cheaper.
Converge the warehouse and lake into one technology, either extending the data
warehouse to include embedded ML training or alternatively building data ware‐
house integrity, transactionality, and querying systems into data lake solutions. Databricks Lakehouse is an example of a traditional lake storage solution with warehouse-like transactions and query support.

The cloud data lake is addressing some of the gaps of the previous generations. Yet, some challenges remain:
Data lake architecture remains very complex to manage, affecting data quality and reliability.
The architecture design remains centralized requiring a team of
hyper-specialized data engineers.
Long time for insights. Data consumers continue to wait several months to get a dataset for analytics or machine learning use cases.
Data warehouses no longer are a replication of the real world through data, impacting data consumers experience while exploring data.
All of those challenges led us to the fourth-generation data architecture which, at the moment this article is being published, is still in the early days.
Fourd Generation: Data Mesh Architecture
Data mesh architecture is a relatively new approach to data architecture that seeks to address some of the challenges that were identified in previous centralized architectures.
The data mesh brings to the data architecture what microservices brought to monolithic applications.
In a data mesh, the data is decentralized and the ownership of the data is distributed across domains. Each domain is responsible for the data within its scope, including data modeling, storage, and governance and the architecture must provide a set of practices to enable each domain to manage its data independently.
Here are the key components of a data mesh architecture:
Domains - A domain is a self-contained business unit that owns and manages its own data. Each domain has a clear business purpose and is responsible for defining data modeling, entities, schema, and policies to govern data.
This concept is different from data marts in data warehouse architecture designed for different teams such as marketing or sales. In a data mesh architecture, sales can have multiple domains, depending on the different focus/areas the team might have.
Data Products - A data product is the end result of what is produced by the domain and is made available for consumption to other domains or applications. Each data product has a clear business purpose.
One domain can be handling several data products. Not all data assets will be considered a data product or should receive a data product treatment (although in the perfect world that would be the case). Data products are data assets that are playing a key role in the organization.
Data Infrastructure - Data infrastructure includes the tools and technologies needed to manage data within a domain, similar to a containerized microservice for a software application. This includes data storage, processing and analysis tools.
Data Governance - Data governance is managed by each domain. This refers to the set of procedures to govern data quality, privacy, and security.
Mesh API - Just like a microservice exposes everything via HTTP REST APIs, a data mesh domain would expose everything via a well-defined interface that could be consumed by other domains and data products.

You can see data mesh as a paradigm shift in how data architecture is designed and how data teams are organized nowadays:
Data teams become cross-functional teams that are specialized in one or more business domains (not technology), just like software product teams are very service oriented.
Every business domain composed of one or multiple microservices would have its own OLAP database and distributed file storage system, just like any piece of a microservice is containerized to work independently.
Data product A will be consumed by Data Product B and both will be communicating with other data products through streaming or REST API, just like application microservices communicate with each other.
Data Product APIs will be followed by the traditional REST API documentation, and data products can be discoverable via the mesh data catalog.

What else changes with data mesh besides the architecture?
The most impactful change from data mesh is the architecture. But moving from a centralized data lake to a decentralized data mesh is a socio-technical phenomenon, that implies several additional changes.
If you recall, the transition from monolith applications to microservice applications made software engineering teams change their development life-cycle, organizational structure, motivations, skills, and governance. That’s when the role of product manager emerged to ensure applications would be solving real user problems.
The same needs to happen while applying a data mesh architecture.
In the upcoming articles, I will be writing more about the challenges of data mesh implementation.
If you want to read more content make sure to follow me on LinkedIn for more weekly posts, and if you liked my article, please consider subscribing.
Thank you so much for reading and let’s talk again soon.
Follow up question, what are the main challenges of the data mesh architecture?
How is the data mesh addressing the key challenges mentioned in the data lake and lake house architecture?